Конкурс Open AI Caribbean Challenge на платформе DrivenData
В конце декабря 2019 г. завершился конкурс по машинному обучению Open AI Caribbean Challenge, в котором приняла участие команда специалистов ООО КодЛикс. Конкурс проводился на платформе DrivenData и собрал 1425 участников со всего мира. Далее мы хотим поделиться нашим первым соревновательным опытом в подобных мероприятиях.
Описание задачи
Задача конкурса заключалась в определении типа материала крыши различных зданий и сооружений по материалам воздушной съемки. В качестве исходных данных выступали 7 ортофотопланов местности с плотной застройкой на территории Колумбии, Гватемалы и Сент-Люсии разрешением от 3.6 до 4.5 см / точку в формате GeoTIFF в проекционной системе координат WGS84 UTM (зоны 18, 16 и 20 северного полушария).
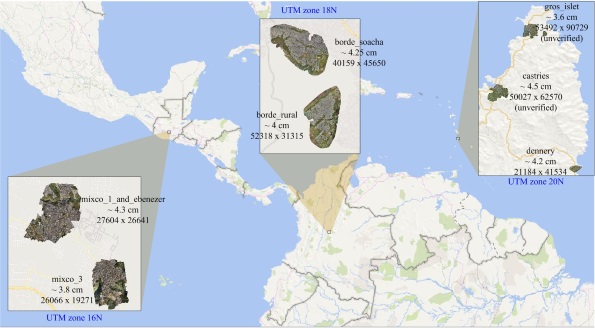
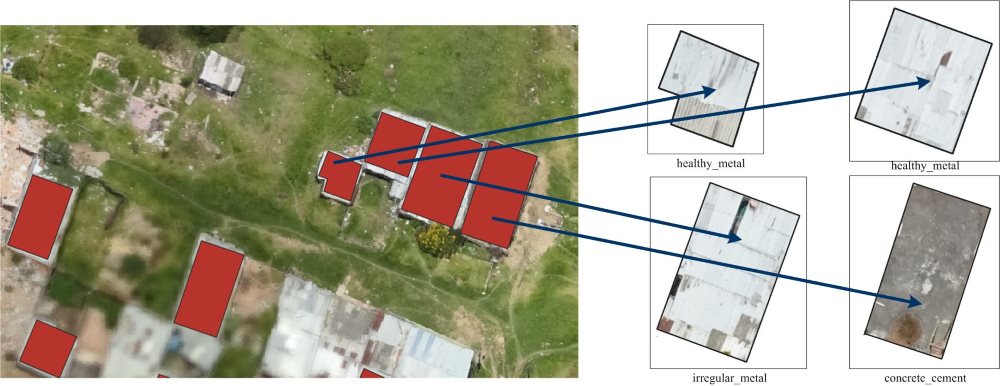
Каждому снимку соответствовало два файла разметки в формате GeoJSON: тренировочный и тестовый. Положение каждого из объектов описывается полигоном в геодезических координатах (WGS84). На снимке тренировочные и тестовые объекты смешаны произвольно, как показано на рисунке ниже (красным изображены объекты тренировочной выборки, желтым - тестовой).

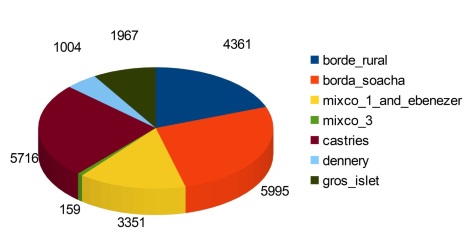
Количество объектов на каждом из изображений приведено на диаграмме ниже.
Тестовая выборка отличается от тренировочной только пустым полем типа крыши, которых по условиям конкурса всего 5: «concrete_cement» (бетон), «healthy_metal» (металл), «incomplete» (недостроенное/разрушенное), «irregular_metal» (разнородный металл) и «other» (прочие).
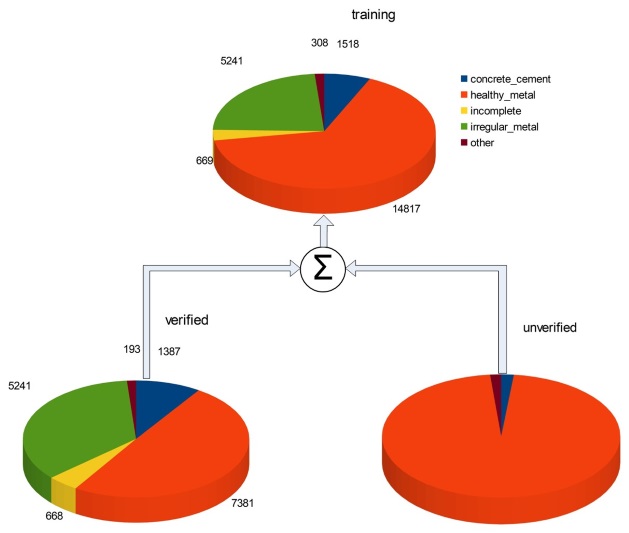
Особенность исходных данных в том, что часть обучающей выборки является неверифицированной (unverified) – два снимка на территории Сент-Люсии – которые размечены с помощью алгоритмов машинного обучения. Тестовой разметки на этих снимках нет, поскольку организаторы предполагали, что эти данные можно использовать для обучения на свой страх и риск: положительный эффект от обучения алгоритма на основе разметки другого алгоритма не гарантирован.
Диаграммы распределения тестовых объектов по классам для всей обучающей выборки (training), созданной вручную (verified) и неверифицированной (unverified) приведены ниже.
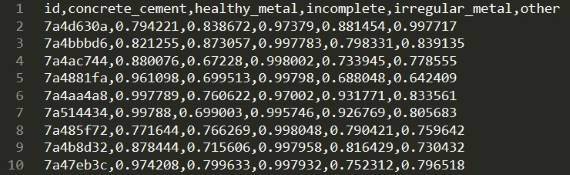
Результаты классификации тестовых объектов должны быть представлены в сводном CSV-файле, в котором каждому объекту отводится отдельная строка, содержащая идентификатор и значения степеней его соответствия каждому из классов в диапазоне [0,1]. Пример такого файла приведен ниже.
Итоговая оценка рассчитывается на основе суммы по всем классам и объектам тестовой выборки значений логистической функции потерь logistic loss, которая, как показала практика, очень жестко штрафует за неправильные ответы.
Конвейер
Для реализации конвейера мы использовали следующий стек технологий:
● С++ – основной язык программирования;
● GDAL+PROJ – работа с GeoTIFF и преобразование координат;
● darknet – работа с нейронными сетями (использован форк от AlexeyAB, поскольку он имеет больше вариантов конфигурации и способен на одном графике отображать как функцию потерь, так и точность на валидационной выборке).
Первой задачей было создать конвейер для:
а) подготовки обучающей выборки и обучение YOLOv3;
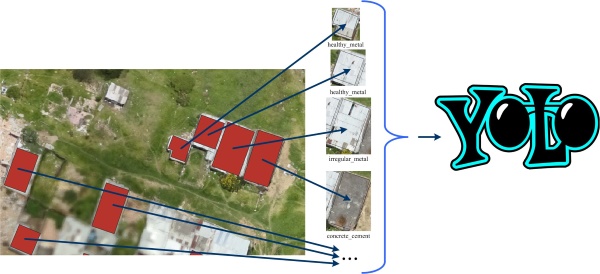
б) подготовки тестовой выборки, предсказание и создания CSV отчета.
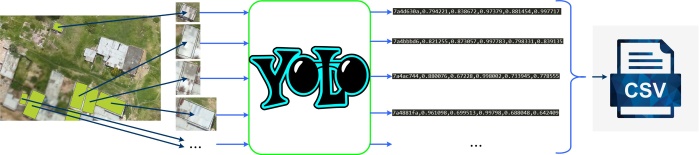
Подготовка данных и постпроцессинг
В ходе первоначального планирования было решено, что обучающая и тестовая выборки будут представлять собой наборы фрагментов, каждый из которых центрирован относительно определенного объекта и содержит его целиком. Для преобразования географических координат полигона из исходного GeoJSON в растровые координаты в пределах соответствующего GeoTIFF использована следующая последовательность операций, реализованных средствами библиотек GDAL и PROJ:
1) геодезические координаты WGS84 полигона преобразованы в проекционные WGS84 UTM (номер зоны зависит от конкретного GeoTIFF), используя класс OGRCoordinateTransformation;
2) проекционные координаты преобразованы в растровые с помощью инвертированной (GDALInvGeoTransform) матрицы аффинного преобразования координат (GDALDataset::GetGeoTransform, GDALApplyGeoTransform);
3) для полученного полигона в растровых координатах определить описанную рамку, вырезать по ней фрагмент, при необходимости, отмасштабировать к требуемому размеру;
4) записать атрибутивную информацию: id объекта и его тип (для обучающей выборки).
Для создания CSV файла с результатами предсказания мы использовали рассчитанную YOLOv3 степень принадлежности тестового объекта каждому из пяти классов.
Варианты тренировки YOLOv3
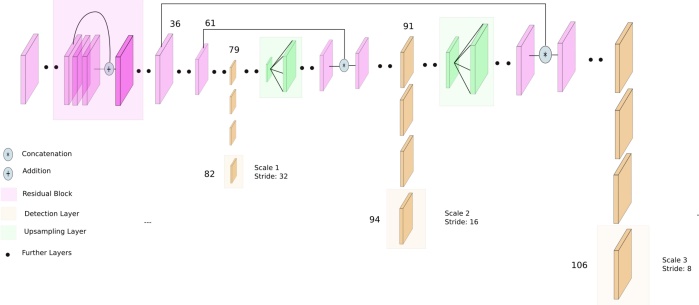
Предсказание типов крыши зданий выполнялось с помощью YOLOv3 в стандартной конфигурации (ее структура приведена на рисунке ниже, источник) и c пятью масштабными слоями для предсказания.
Выбор YOLOv3 как основной сети обусловлен ее успешным применением в ранее выполнявшихся нашим коллективом проектах. Выбор неоднозначный, поскольку конкурсная задача предполагает классификацию, тогда YOLOv3 – в первую очередь быстрый детектор объектов, и лишь во вторую – классификатор. И, тем не менее, мы решили попробовать…
Посмотрев на диаграмму распределения классов для неверефицированной выборки, мы без сомнений решили ее не использовать, поскольку она является моноклассовой (~97% ее относится к и без того наиболее представительному классу «healthy_metal») и разбалансирует выборку.
После создания конвейера мы создали обучающую и тестовую выборки, вырезав здания по разметке как есть (без масштабирования), обучили YOLOv3_5l в исходной конфигурации (график обучения приведен ниже) и выполнили предсказание на тестовой выборке.
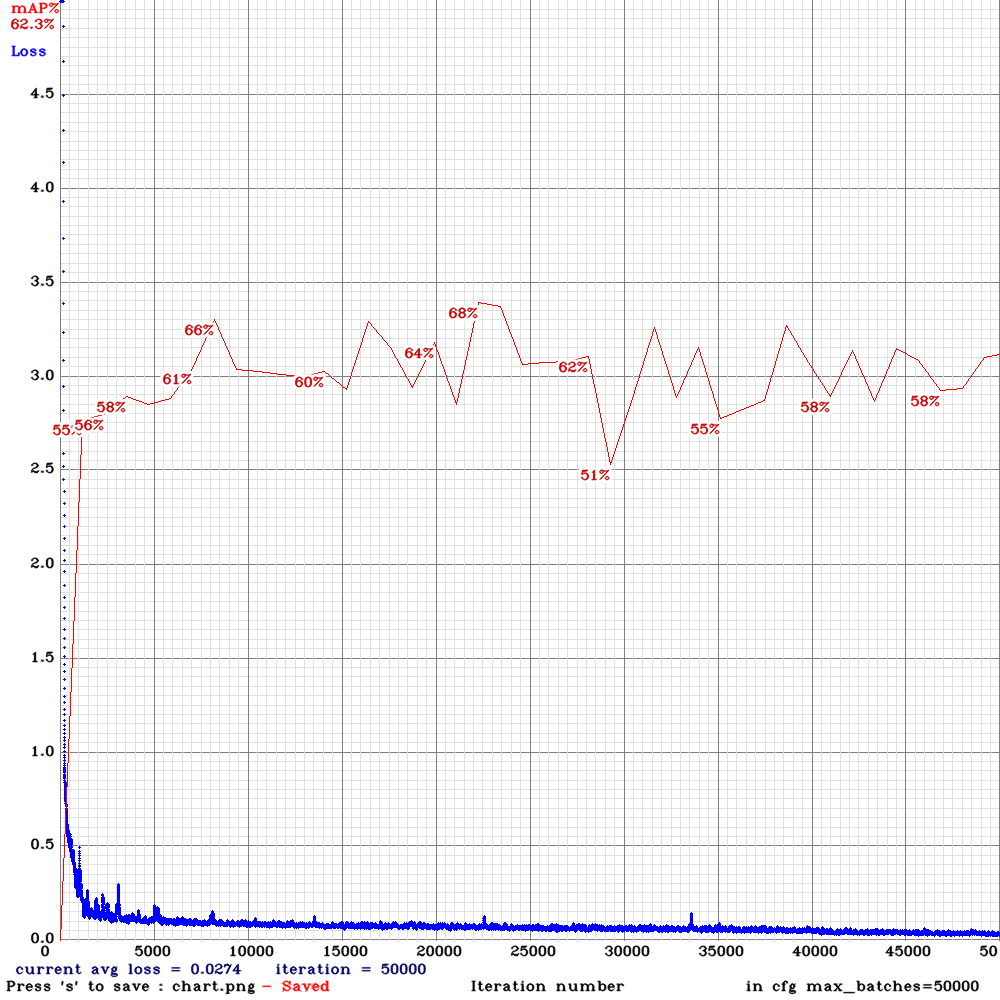
Первый сабмит был создан с помощью пороговой постобработки – для каждого объекта выбран класс с наибольшей степенью принадлежности, который отмечался единицей – остальные классы – нулями. Результат: 28.99 – катастрофический с учетом того, что метрика представляет собой функцию ошибки и квалифицируется по принципу «меньше-лучше». Даже у базового Resnet-18, выложенного организаторами в качестве baseline на MATLAB, результат был много лучше: 2.1871!
Очевидно, что бинарная классификация результата приводила к очень большим штрафам со стороны логистической функции ошибки, поэтому в последующих сабмитах мы использовали степени принадлежности напрямую от YOLO, лучший результат для 21k эпохи стал 1.6128. Отлегло… Хотя в рейтинге первое место занимала команда с 0.34, был стимул двигаться дальше.
Первая идея по улучшению результата: уменьшить размер входного изображения. Особенность YOLOv3 в том, что входное изображение она разбивает на заданное число тайлов, чтобы в процессе обучения помещаться в имеющийся объем памяти. Для обучения мы использовали две NVIDIA GeForce 2070 8Gb. Библиотека darknet, в отличие, например, от Tensoflow не умеет объединять память нескольких установленных GPU в единое пространство для тренировки моделей большего размера, а запускает на разных ускорителях параллельно разные эпохи, получая прирост в скорости обучения. Так, для исходной конфигурации YOLOv3_5l входное изображение размером 416x416 разбивалось на 24 тайла (далее форма записи будет 416х416х24), что позволяло модели занимать не более 7Гб каждого GPU при обучении. Снижение размера входного изображения позволило решить две задачи:
1) снизить негативное (зашумляющее) влияние высокой детализации текстур крыш;
2) увеличить размер предъявляемой при обучении части относительно целого объекта.
В итоге решили остановиться на следующих вариантах: 256х256х12, 128х128х4, 96х96х2.
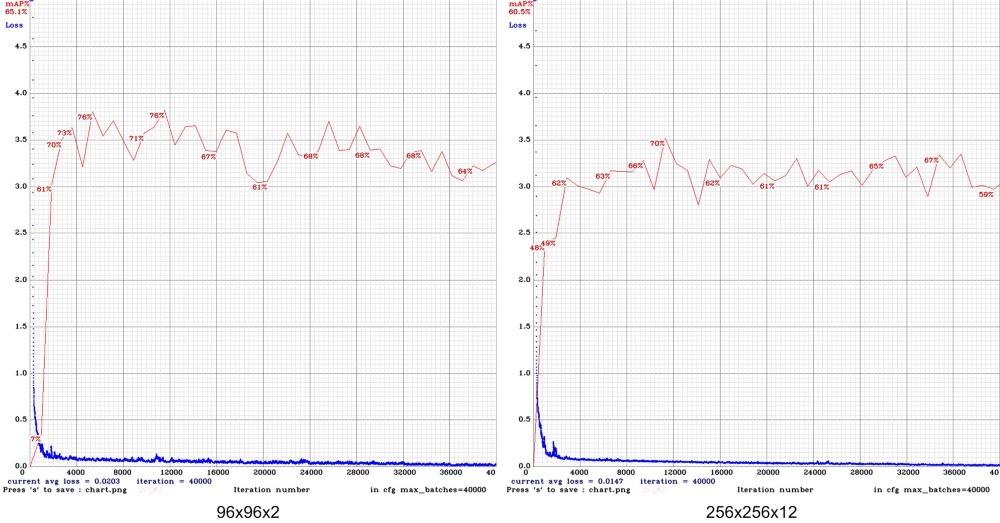
В результате лучшим оказался вариант 128х128х4: 1.5440 (его график обучения, к сожалению, не сохранился, но он мало отличался от приведенных выше). Остальные – несколько хуже: 256х256х12 - 1.5837, 96х96х2 - 1.6509.
Следующая мысль – попробовать при предсказании меньшее количество тайлов, чем при обучении, что давало немного лучший результат. Так конфигурация 128х128х4/2 позволила получить наилучший результат 1.5388 и занять итоговое 107 место.
Также мы рассматривали другие варианты улучшения результата.
Первый вариант заключался в том, чтобы маскировать в обучающей и тестовой выборке часть изображения, не входящую в полигон белым цветом, дабы в плотной застройке текстуры смежных зданий не мешали друг другу.
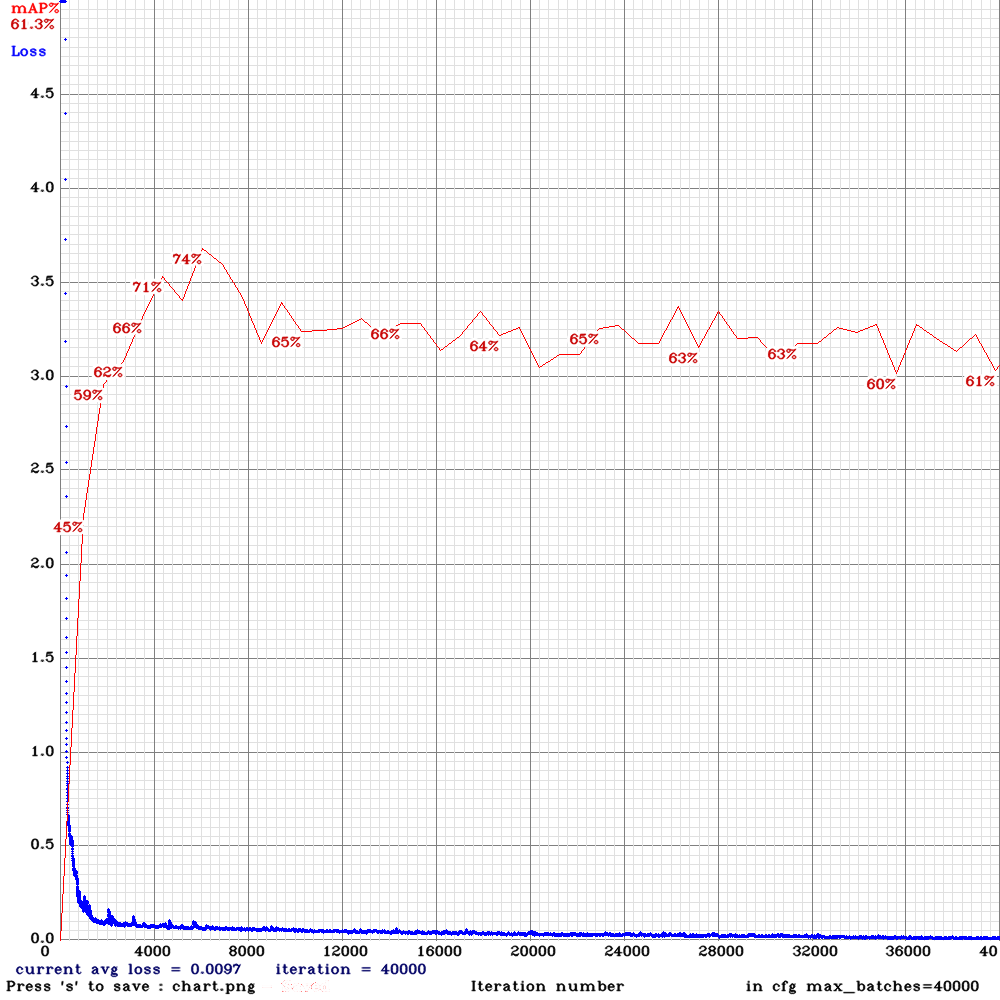
Решение оказалось не очень удачным (график обучения конфигурации 224x224x8 приведен ниже, результат 1.6933), так как, по всей видимости, нейронная сеть из-за очень контрастных границ в большей степени стала ориентироваться на форму объектов, нежели чем на текстуру.
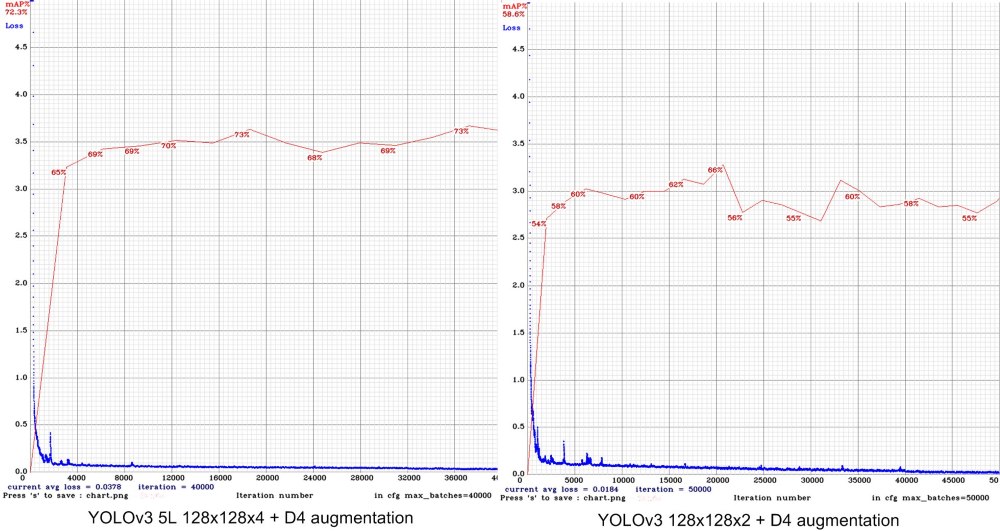
Второй вариант родился из анализа графиков точности на валидационной выборке в процессе обучения, который достаточно быстро достигает насыщения (за 6-12k эпох) и далее постепенно начинает снижаться. Возникло предположение, что обучающей выборки недостаточно и следует попробовать использовать аугментацию путем последовательного поворота изображения на 90 град. Положительного эффекта это не дало, лучший результат для 128х128х4 - 1.5805. Также попробовали стандартный вариант YOLOv3 с тремя масштабными уровнями в конфигурации 128х128х2 (2 тайла получилось сделать за счет меньшего размера модели) - 1.6554.
Также, без особого успеха, пробовали исключать малопредставительные GeoTIFF mixco_3 и dennery.
Последний протестированный вариант улучшения: изменить принцип создания обучающей и тестовой выборки, проходя окном фиксированного размера по изображению с шагом, равным половине этого окна, и включать в выборку все фрагменты, которые содержат не менее 20% точек объектов из обучающей выборки (как показано на следующем рисунке).
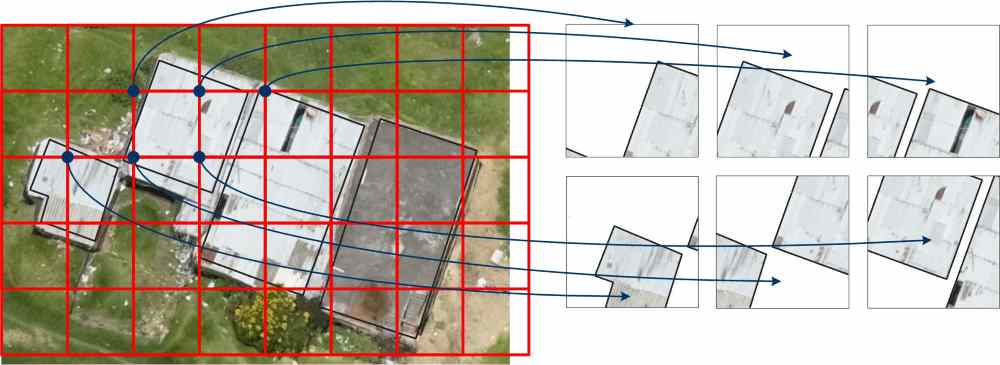
Были протестированы варианты обучающей и тестовой выборки для обучения YOLOv3 5L с окнами размера 256х256 (вход сети 128x128x4) и 416х416 (вход сети того же размера), лучшие результаты: 1.5881 и 1.6064, соответственно. Графики обучения приведены ниже.
На первый взгляд графики точности выглядят значительно перспективнее полученных ранее, однако, по факту, рост показателя mAP оказался обусловлен повышением точности локализации, а не классификации объектов.
Послесловие
Уже в процессе написания данной статьи и медитирования на наши результаты предсказания пришла мысль о том, что мы уперлись в значение 1,5 из-за сочетаний особенностей конкурсной оценки, а именно, жестких штрафов за значительные промахи (более 0.6) и результата классификации от YOLOv3. Большая часть любого из наших конкурсных сабмитов выглядит так:
0.794221, 0.838672, 0.97379, 0.881454, 0.997717
т.е. все оценки степени принадлежности лежат в диапазоне [~0.8,1]. Это, видимо является особенностью YOLOv3, поскольку никакими модификациями обучающей выборки, принципа ее подготовки и параметров обучения иного результата добиться не удалось. Для классификации при решении задачи обнаружения объектов этого достаточно – просто выбираем класс с наибольшим значением. А логистическая функция ошибки оценивает приведенный выше результат в 1.84, если истинным является пятый класс с максимальной оценкой и в 2.78 – если истинный первый.
Тогда родилась мысль отмасштабировать диапазон [min,max] в [0,1]. В таком случае, оценка для истинного первого класса стала бы 3 (т.е. повысилась всего на 0.22) для истинного пятого класса стала бы 0.57 (а это на 1.27 меньше!). Жаль, попробовать этот трюк не удалось…
Первый опыт нашего участия в конкурсах показал, что качество постобработки результата под конкурсную метрику не менее важно, чем качество самого решения.
К слову, на DrivenData проходит новый конкурс по обработке аэросъемки, в котором наша команда также принимает участие. Следите за публикациями.
КодЛикс разрабатывает программное обеспечение обработки изображений, систем технического зрения, искусственный интеллект и нейросети. Мы создаём программное обеспечение любой сложности под ключ и с гарантией.