Статистика алгоритма обнаружения лиц на основе HOG
- Информация о материале
- Опубликовано: 06.09.2018, 14:41
Проведено исследование алгоритма обнаружения лиц на основе гистограмм направленных градиентов (HOG) библиотеки dlib на 10000 размеченных изображений базы Megaface для определения количества ошибок второго рода (ложных отрицательных срабатываний) и причин их возникновения.
Количество ошибок второго рода составило 3251 (~32,5%). Большая часть ошибок допущена на снимках в естественных условиях (Wild Faces) и изображениях малого размера.
Ведется первая доработка алгоритма, нацеленная на преодоление ограничения по размеру лица путем увеличения изображения.
Основные причины ошибок:
1. Малый размер лица. Согласно описанию разработчиков детектор dlib нечувствителен к лицам, размер которых составляет менее 40х40 точек (face_detection_ex.cpp). Количество ошибок ~15% от общего количества протестированных изображений.








2. Изображение лица в профиль. Детектор настроен на фронтальное положение лица в кадре и для снимка в профиль не находит требуемых признаков. Количество ошибок ~10% от общего количества протестированных изображений.








3. Голова наклонена вниз. На снимке не видны глаза и изменены пропорции лица. Количество ошибок ~0.1% от общего количества протестированных изображений.



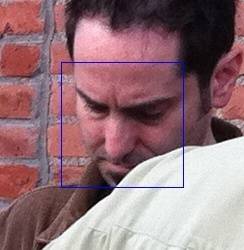

4. Размытие изображения от движения объекта (motion blur) и расфокусировка при съемке. Размытое изображение лица не дает четких откликов. Количество ошибок ~0.5% от общего количества протестированных изображений.







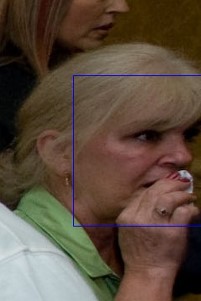
5. Лицо расположено близко к краю кадра или частично перекрыто другими объектами. Отсутствие полного изображения лица не позволяет сформировать однозначный отклик. Количество ошибок ~4% от общего количества протестированных изображений.







6. Изображения детей. Расположение ключевых точек (landmarks) лица детей отличаются от таковых у взрослых, следовательно, детектор HOG, настроенный на изображения взрослых, не реагирует на них. Количество ошибок ~1,5% от общего количества протестированных изображений.




7. Очки, головной убор, грим на лице, прическа, частично закрывающая лицо. Количество ошибок ~0,1% от общего количества протестированных изображений.








8. Зашумленное изображение из-за низкого разрешения датчика, съемки при слабой освещенности, сканирования изображения с бумажного носителя. Количество ошибок ~0,5% от общего количества протестированных изображений.








9. Особенности освещения лица, сочетание света и тени. Количество ошибок <0,01% от общего количества протестированных изображений.



Большая часть нераспознанных изображений сочетает в себе совокупность перечисленных причин.
КодЛикс разрабатывает программное обеспечение обработки изображений, систем технического зрения, искусственный интеллект и нейросети. Мы создаём программное обеспечение любой сложности под ключ и с гарантией.